企业大模型AI数字化建设思路-背景、趋势与动机
1 大模型技术带来的发展机遇
1.1 技术变革背景
大模型引领变革
- ChatGPT:2023年OpenAI发布, 彻底重塑自然语言处理技术,引发全球关注。
- DeepSeek:2025年1月,国产推理模型性能卓越,成本低,App登顶多国下载榜,日活突破2000万,成为全球增长最快的APP。
国家宏观政策支持
- 政策文件:
- 《生成式人工智能服务管理暂行办法》:鼓励创新,包容审慎监管。
- 《关于加快场景创新以人工智能高水平应用促进经济高质量发展的指导意见》:推动AI与实体经济融合。
- 政策导向:国家支持AI技术在各行业的创新应用,构建应用生态体系。
1.2 从 Scailing Law规模定律窥见AI 技术的未来趋势
1 大模型能力的规模定律:模型性能与规模呈现指数关系。大模型能力发展远未触顶。
在规模定律的作用下,大模型带来三重能力突破

规模定律的新发现:普遍认为,随着可获取的训练数据逐渐见顶,规模定律将失效。然而,以 OpenAI O1 和 DeepSeek R1 为代表的技术突破表明,规模定律在两个新方向将持续有效:
大模型的规模定律
| 1.后训练优化 | 2.推理机制创新 |
|---|---|
| 以强化学习技术为核心来增强模型的自主探索学习能力 | 更长的思考时间带来更强的解决问题能力 |
| 模型甚至涌现自我反思能力 | 模型学会了自我思考,用户体验获得质的提升 |
总之,随着新的规模定律要素的发现,大模型技术远未触及天花板,预期未来仍有广阔的发展空间。
2 大模型成本的规模定律:模型能力密度随时间呈现指数增长。大模型的计算成本在快速下降。
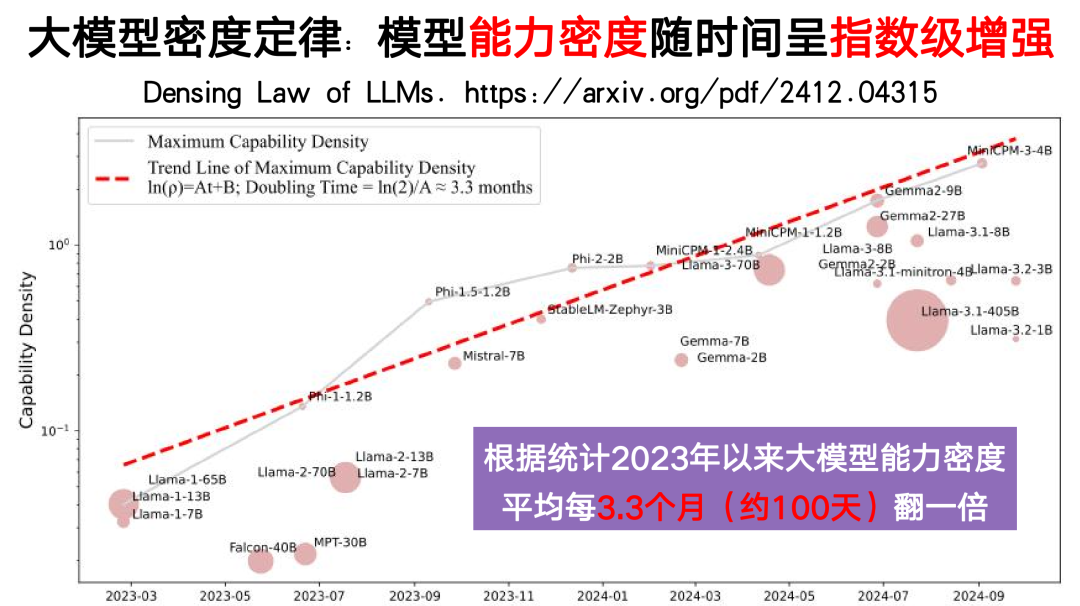
从2023年开始,大模型展现出显著的能力密度提升规律:
- 指数增长趋势:自2023年以来,LLM的最大能力密度约每3.3个月(约100天)翻一番、相同能力只需一半参数量、计算成本随之降低50%
- 预测:根据拟合曲线,到2025年底,仅需8B参数的模型即可达到GPT-4级别的性能。
重要推论
- 推理成本下降:模型推理开销随时间指数级下降。例如,2022年GPT-3.5的推理成本为每百万Token 20美元,2024年同类模型成本降至0.075美元。
- 端侧智能潜力:芯片电路密度(摩尔定律)与模型能力密度(密度定律)的协同增长,推动手机等终端设备运行高性能模型。
就像芯片工业在摩尔定律指引下推动了信息革命,能力密度的指数级增长正在推动AI革命,使其逐步走向普惠化、平民化。
1.3 大模型时代的战略机遇
基于能力规模和成本规模的双重突破,大模型正加速企业数字化转型:
企业机遇
- 激活数据智能:释放数据要素潜能,构筑企业数智化引擎。
- 重塑业务模式:重构企业核心流程,催生创新业务增长点。
- 扩展价值网络:打破组织边界,实现生态共赢。
行动指南
- 战略先行:把握AI变革机遇,赢得未来竞争优势。
- 敏捷创新:快速迭代,在实践中探索AI赋能的最佳路径。
- 夯实数据基础:构建企业级数据资产,驱动智能化应用。
2 企业AI 数字化建设失败是常事-处处皆陷阱
| 🤖 零售企业AI客服系统 | 🏦 金融企业AI反欺诈系统 | 🏭 制造企业AI排障系统 |
|---|---|---|
| 背景: 该零售企业希望通过 AI 客服系统降低人工客服成本,提高服务效率 | 背景: 该金融企业希望通过 AI 信用卡盗刷检测系统,实时监控交易,减少盗刷造成的损失 | 背景: 该制造企业希望通过 AI 排障系统,帮助工程师快速诊断和解决精密设备的故障,减少停机时间 |
| 问题: 数据质量不高,由于存在过时、缺失、错乱的信息(例如未及时更新的库存数据、FAQ 更新不及时、不同 SKU 的特性参数未明确区分等),导致 AI 客服给出了错误的回答 | 问题: 模式漂移,最初,AI 系统能够有效地识别盗刷行为,但随着时间的推移,盗刷者的手段不断演变,原有的盗刷模式发生了变化(即模式漂移)。由于该 AI 系统未能及时适应新的盗刷模式,导致检测准确率大幅下降 | 问题: 场景复杂性过高,该 AI 排障系统试图覆盖所有精密设备的故障诊断,涉及上百个零部件以及多种不同的状态。由于系统本身是一个复杂系统,且企业在排障领域的 AI 案例积累不足,导致系统难以有效训练和应用,无法准确识别故障原因并给出解决方案 |
| 结果: AI 客服系统上线后,不仅没有降低人工客服成本,反而因为客服错误频繁,导致用户投诉增加,人工客服需要花费更多的时间处理投诉,最终项目失败 | 结果: AI 信用卡盗刷检测系统上线一段时间后,盗刷损失金额开始上升,系统未能有效识别新型盗刷行为,最终导致大量用户资金被盗,企业不得不投入大量资源进行赔付和系统升级 | 结果: AI 排障系统上线后,工程师在使用过程中发现系统经常给出错误的诊断结果,甚至会误导排障方向,最终导致排障效率降低,项目最终被放弃 |
| 教训: 确保高质量的数据输入,提前做好数据治理 | 教训: AI 系统必须建立持续的监控、反馈和迭代机制,才能保证其长期有效性 | 教训: 对于复杂系统,AI 建设需要从简单场景入手,逐步积累案例和经验,再扩展到更复杂的场景 |
3 企业 AI 数字化建设的五大陷阱与挑战
🚀 1 战略陷阱:盲目追求 AI 转型,缺乏明确的业务目标
许多企业盲目跟风,将 AI 等同于高大上的深度学习或大模型,却没有思考"为什么需要 AI"和"AI 能解决什么问题"。结果就是投入大量资源建设 AI 能力,最终却发现与业务诉求不匹配,沦为华而不实的技术展示
🎯 2 方案陷阱:过度追求高端场景,操之过急忽视落地难度
总想一步到位实现最有价值最高端的业务场景落地,却忽视了技术实现的可行性与复杂性。最终往往是"理想很丰满,现实很骨感",系统难以落地,即使勉强上线也难以持续运营
📊 3 要素陷阱:数据基础薄弱,缺乏系统的数据治理与知识工程建设
幻想着通过几个月的数据治理就能建立起高质量的数据基础,却低估了数据标准化、数据清洗、数据更新的长期投入。没有持续的数据治理机制,再先进的 AI 模型也只能是"垃圾进,垃圾出"
🤝 4 执行陷阱:跨部门协作不畅,项目推进受阻
AI 项目需要业务、数据、技术、财务等多个部门配合。跨部门合作中的权责不清、流程繁琐等问题,往往导致项目严重延期,错失市场机会。一个原本3个月的项目可能拖延半年甚至更久,最终可能不了了之。
🔄 5 运营陷阱:缺乏持续优化机制,无法应对业务变化
将 AI 系统视为一次性的工程项目,上线即完工。却忽视了业务场景在不断变化,用户行为在持续演进。没有建立持续优化的机制,AI 系统的效果必然会随时间衰减,最终被淘汰
4 从 AI 解决问题的层级分类来认知 AI 的能力边界
| 等级 | 定义 | 解释 | 通用应用场景 | 前置条件 | 技术方案 |
|---|---|---|---|---|---|
| Lv1 | 单一事实问答 | 对单一事实证据或知识概念的查询问答 | 文档问答,资源检索,数据查询 | 完备的企业知识文档或数据库 | RAG |
| Lv2 | 多跳型问答 | 需要精准查询多条事实并形成桥接证据链才能解决的问题 | 跨系统问题诊断技术方案验证 | 1. 数据源之间能形成有效关联2. 支持多重查询与结果整合 | 高级RAG |
| Lv3 | 总结型问答 | 需要精准查询大量的或多角度的事实才能解决的问题 | 专项研究总结摘要格式化报告撰写 | 1. 跨部门数据打通2. 结构化数据仓库建设 | RAG+Workflow |
| Lv4 | 可解释型推理 | 高复杂问题,但构建的系统涉及到的业务对象与状态的规模较小,较容易总结,全过程可解释 | 标品选型对比推荐单一对象排障等 | 1. 专家经验数字化2. 因果推理业务规则库 | 专项场景Agent |
| Lv5 | 未知型推理 | 高复杂问题,高复杂系统,难以枚举推理,但是蕴含了大量日常沉淀的业务case,可以通过深度学习专项建模来解决 | 仿真建模分类预测推荐排序 | 1. 成规模的数据集2. 业务专家参与样本梳理3. AI 专家建模 | 专项场景深度学习 |
- 需求复杂度评估:用5级分类法判断问题涉及的系统复杂度
- ROI评估矩阵:横轴为实施难度(数据/算力/专家资源),纵轴为业务价值
- 可行性检查:
- 数据可获得性(结构化/非结构化/数据量)
- 知识明确性(是否有明确的预测标签或者判定规则)
- 容错阈值(99%以上,还是92%以上,还是80%以上)
5 科学方法论-分层分步的建设思路
分层分步建设的科学性
分层建设的必要性:首先从简单的应用开始,逐步扩展和增加复杂度,以减少风险
分步建设的优势:每一阶段都通过反馈进行优化,不断提高系统的稳定性和可靠性
分层分步建设的底层哲学
风险控制:逐步推进可以更好地控制技术风险,避免过早进入复杂应用阶段
灵活性和可调整性:可以根据每个阶段的反馈和市场需求快速调整方案
本文由上海图灵天问智能科技有限公司提供技术支持,转载请注明出处。
